Python 实现经典排序算法(《算法导论》)
一、插入排序
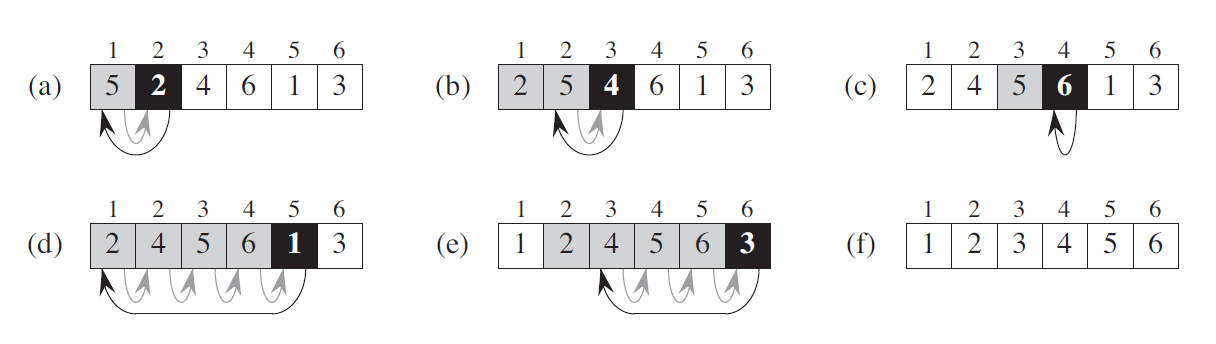
1.1 算法描述

1.2 算法实现
1 | |
二、合并(归并)排序
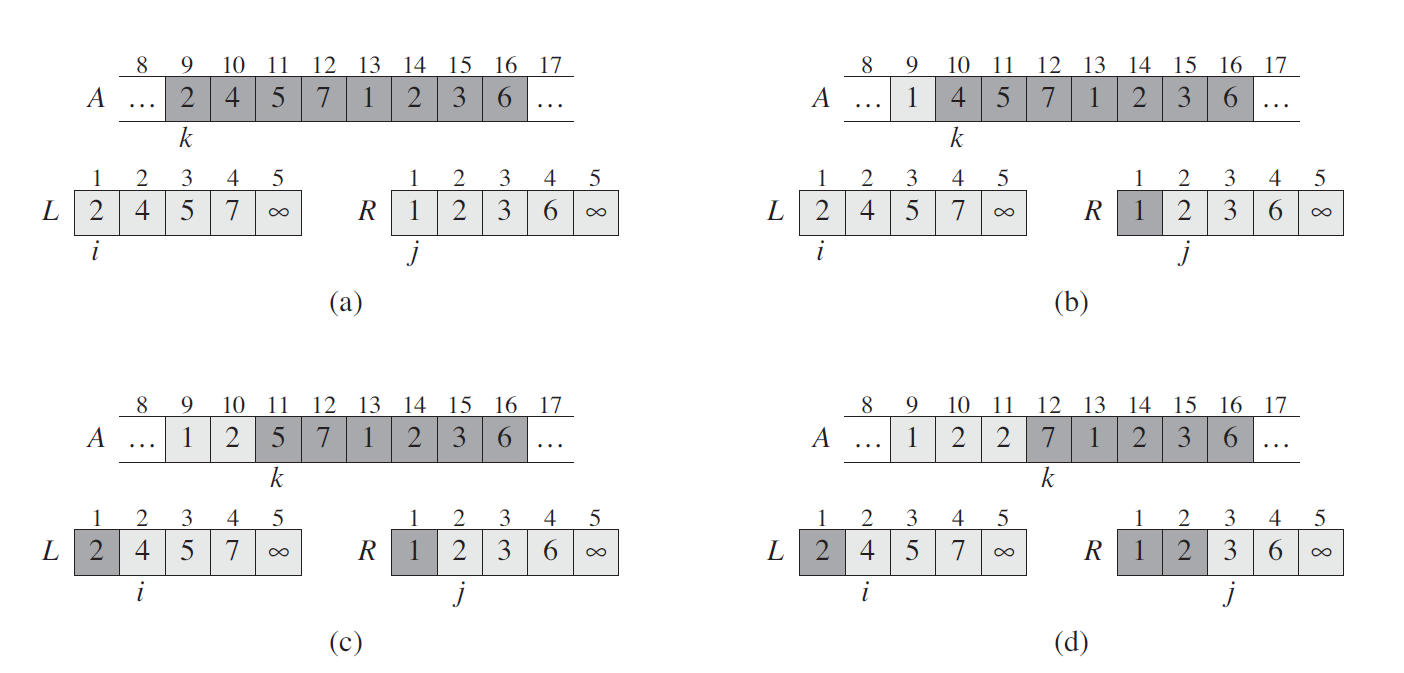
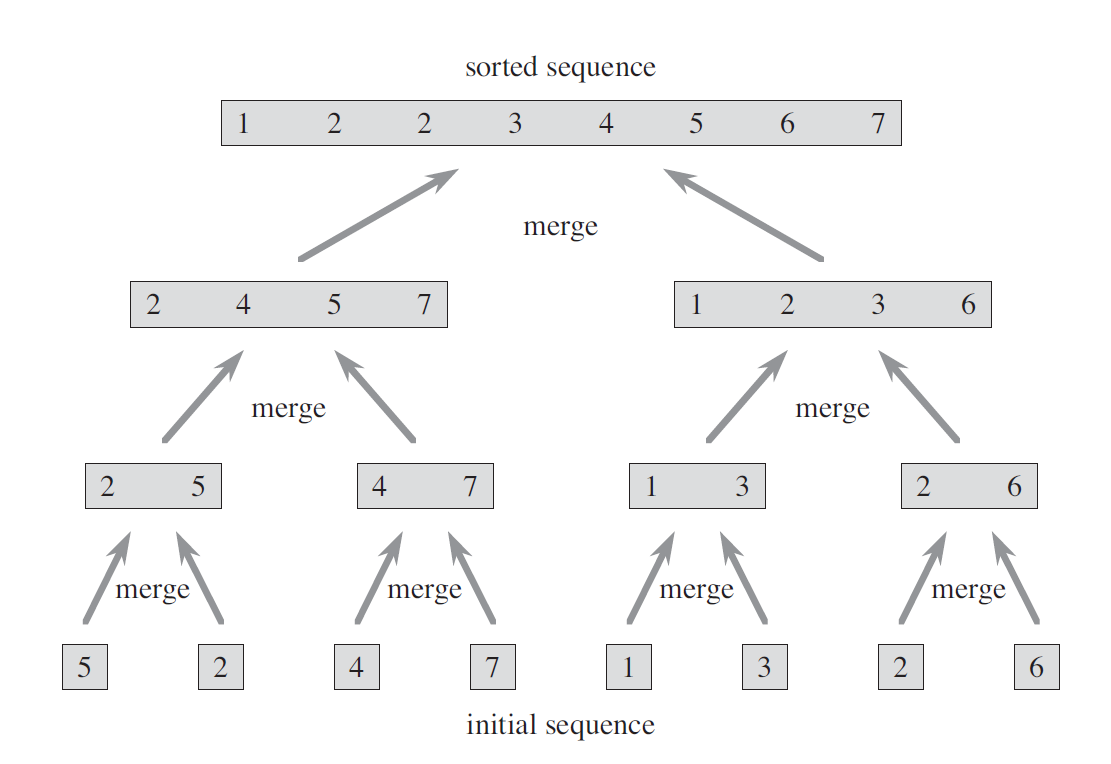
2.1 算法描述

2.2 算法实现
1 | |
三、快速排序
3.1 算法描述


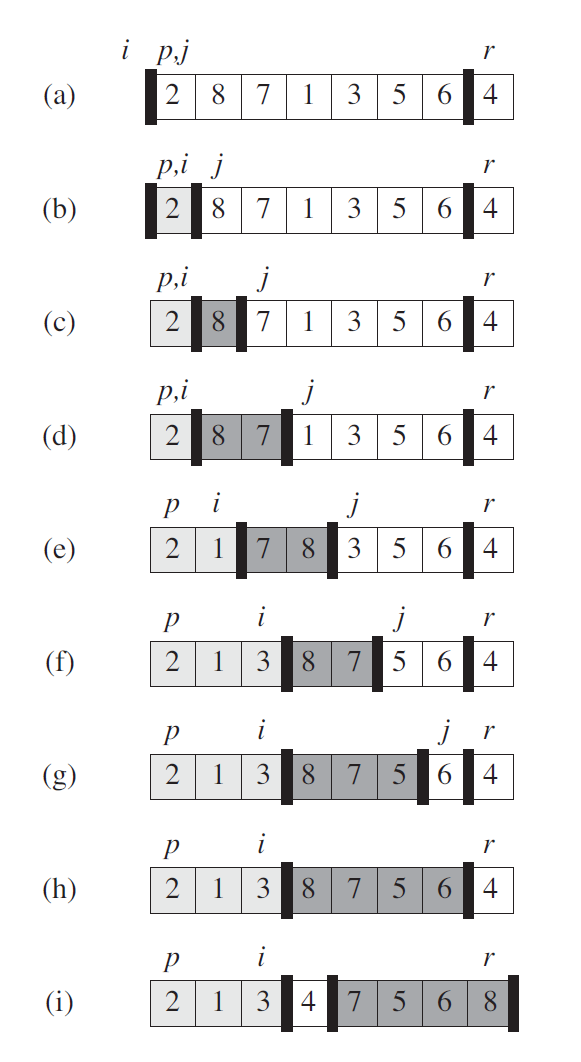
3.2 算法实现
1 | |
四、随机快速排序算法
4.1 算法描述


4.2 算法实现
1 | |
五、计数排序
5.1 算法描述

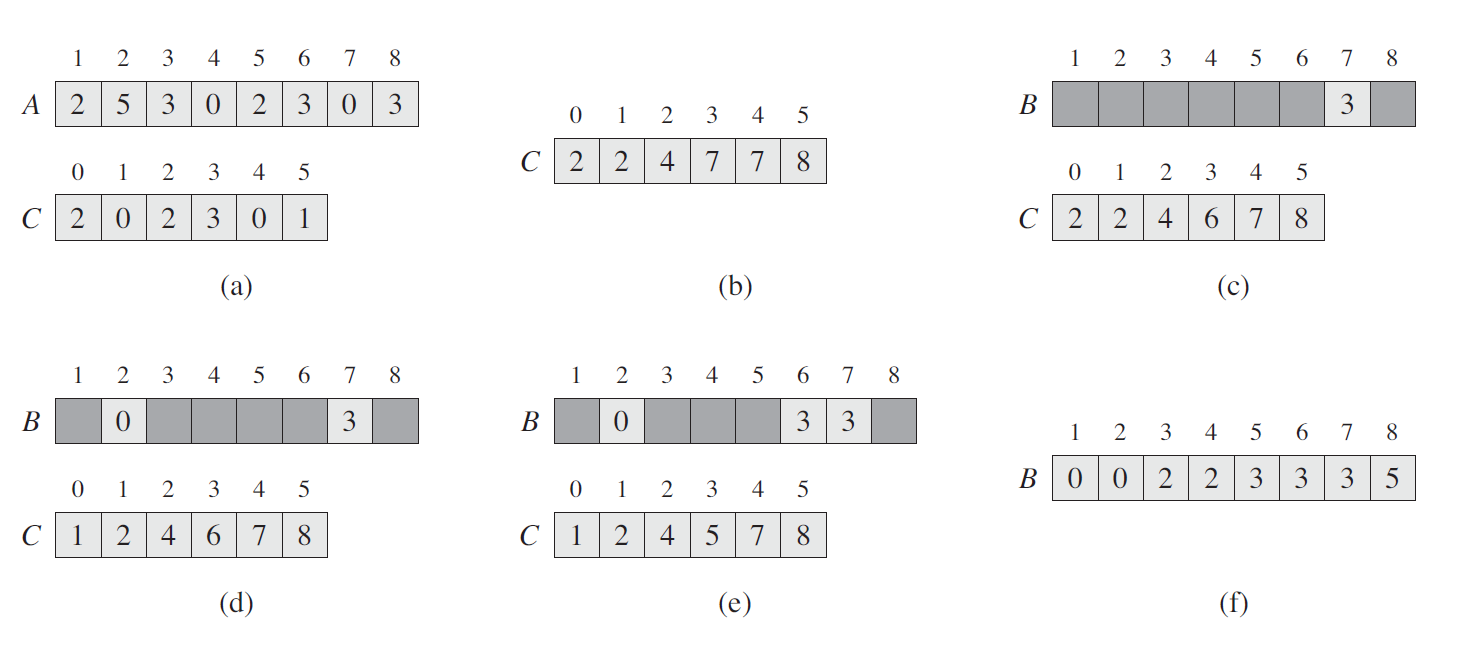
上图是 COUNTING-SORT 在输入数组 A[1..8] 上的处理过程,其中 A 中的每一个元素都是不大于 k = 5 的非负整数。(a) 是第 5 行执行后的数组 A 和辅助数组 C 的情况。(b) 是第 8 行执行后,数组 C 的情况。(c)(e) 分别显示了第 1012 行的循环体迭代了一次、两次和三次之后,输出数组 B 和辅助数组 C 的情况。其中,数组 B 中只有浅色阴影部分有元素值填充。(f) 是最终排好序的数组 B。
这里,(a) 中的 C 数组是计数数组,即记录待排数组中每个数字出现的次数,它的 size 是 A 中最大元素加一,因为它的索引对应的就是 A 中元素的值。(b) 中的 C 数组是 (a) 中的 C 数组中元素从左到右依次累加的结果。
最后往 B 数组中放置元素时,是从 A 中按照倒序的方式依次取元素,再放入 B 中相应的位置的。
5.2 算法实现
1 | |
六、桶排序
6.1 算法描述

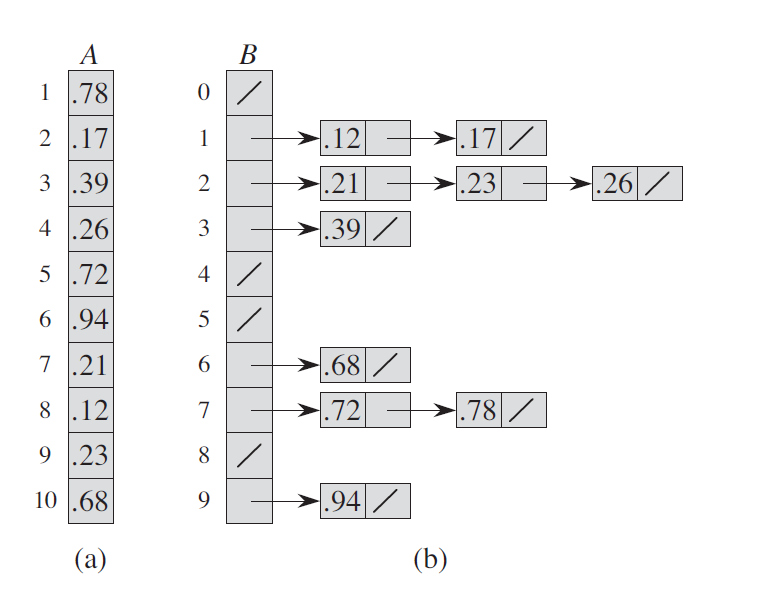
6.2 算法实现
1 | |
七、算法效率可视化
主要是利用 Python 的 matplotlib 这个库,绘制 $T(N)$ 随输入规模的变化的折线图,这里同时绘制三种情况:最好情况(正序)、一般情况和最坏情况(逆序)。
1 | |

这里只绘制了一个插入排序,如果想绘制其他的图像,只需要将代码中的相应的排序方法给替换掉,然后重新跑一遍代码即可。不过,在实际测试时,如果要替换成其他的排序算法来测试,那么,相应地也要调整测试数据(也就是输入的规模),否则快速排序在最坏情况下的递归会耗尽内存。
更新(2021.07.09):在 StackOverflow 找到了一个说法,Python 的递归限制是 999 个调用栈,而且,Python 中似乎没有真正的递归。所以,这个快速排序在 Python 中似乎能用递归实现。然后,我测试了一下 Java 的极限,原来也不是很行啊,到了 100,000 这个级别,就会 StackOverflow 了。
总结
关于这些排序算法,基本都是直接对原数组进行操作的,原因是这里要测试它们的时间效率,所以不便于产生其他额外的开销。但是,在实际运用中,也会有对待排数组的副本进行排序然后返回的情况,这样的好处是不会修改待排的原数组,这一点是要注意的。